tl;dr
To download all photos for a WhatsApp group chat (via Dropbox), I wrote a python scraper to interact with my Android phone via ADB, using tesseract as an OCR layer. The code is ugly, but can be found here OllieF/whatsapp-android-image-scraper.
In this article I talk about the background, options, and talk about the approach.
Background
Last October my mum accidentally broke her phone and with it lost quite a lot of data, primarily photos she had not backed up. Luckily, as the family is quite dispersed internationally, all important photos get shared on the Family WhatsApp group chat, though not in full quality. So when we met up last, she asked if I could get around a year and a half's worth of photos from our group chat off my phone's WhatsApp and send it to her.
Problem
Now while this should be an easy task, getting that amount of images off a single group chat proved to be near impossible to do without going through each image manually, saving it somewhere special and moving onto the next one.
I initially considered the following options:
WhatsApp Backups
I thought that surely this must be a common task, so tried to use the "Chat Settings > More > Export Chat" function, which even asks you if you want to "Include Media" or not. Unfortunately, while this includes a .txt file of the entire chat history, it does not include more than a handful of images. No luck.
WhatsApp images in storage
WhatsApp stores images from all chats on your devices locally, and they can be accessed via the Gallery or the file manager on local storage. However, all images from all chats are stored in the same folder and there are no clear characteristics that would indicate which chat they originated from.
WhatsApp for Web Download
WhatsApp has a web app that can be paired with your phone to use chat on your desktop. This should be easily done, even if some custom scripts have to be written to do browser scraping (via BeautifulSoup or Selenium) or API scraping. The issue was (a) the data fetches were not easily decodable and (b) only the newest n images could be accessed anyway. Disappointing
HTTP traffic scraping
For similar problems, I have historically used something like mitmproxy or Burp Suite to intercept the HTTP(S) traffic and dump its contents to disk. However, after some brief googling, it turns out that the Android WhatsApp app does certificate pinning. Also, everything is end-to-end encrypted, which we love to see, but does not help me in this case.
Solution
In the end, it seemed that the only way this could be scripted was automating the manual steps taken to download the images on the Android itself. To achieve this, I used a combination of the following tools:
ADB (Android Debug Bridge) - tool used to interact with your Android phone in an automated manner for debugging, development, and, in this case, automation.
pure-python-adb link - library to interact with the adb directly from python
tesseract link - Optical Character Recognition (OCR) app used to identify the location of text on screen
scrcpy link - tool used to mirror an Android device via USB to the desktop and interact with it. This was only used to assist with development and was not required
Demonstration
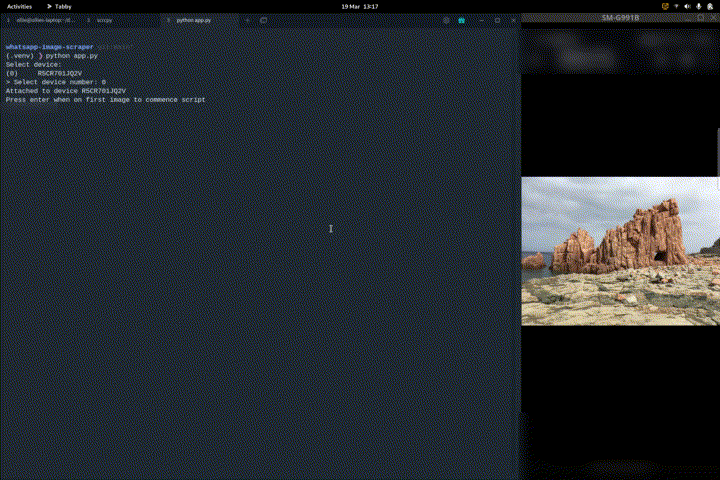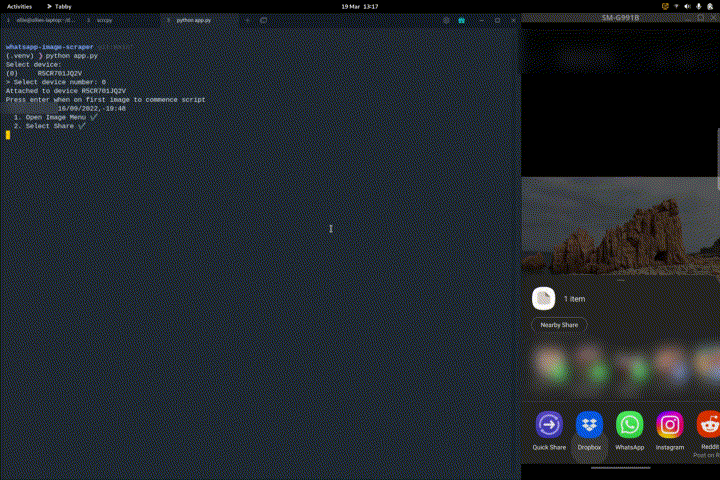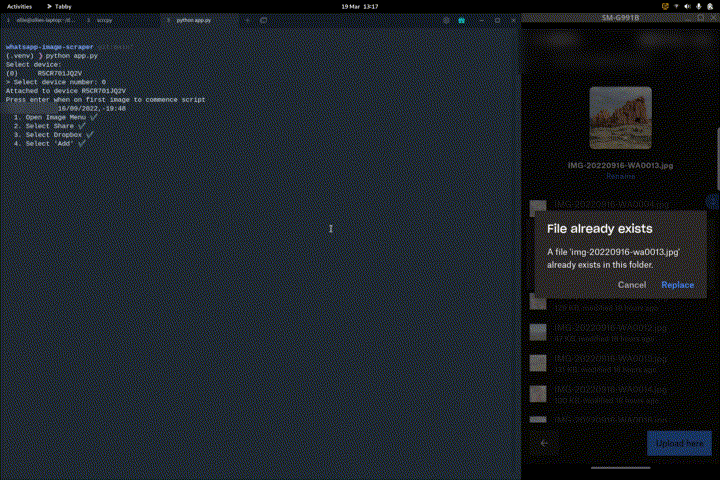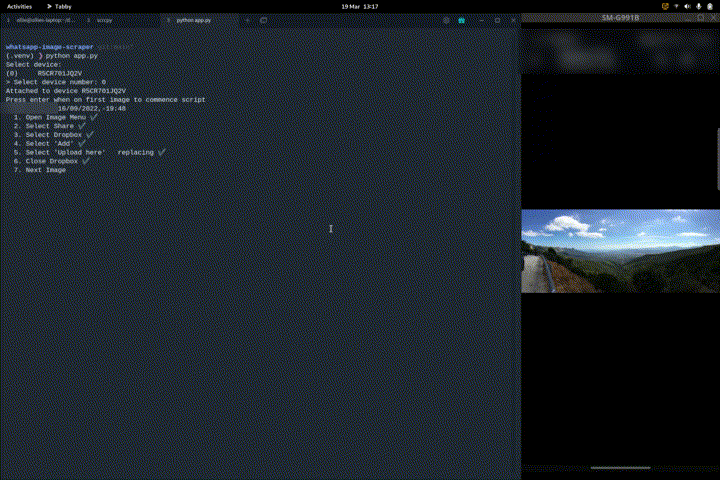
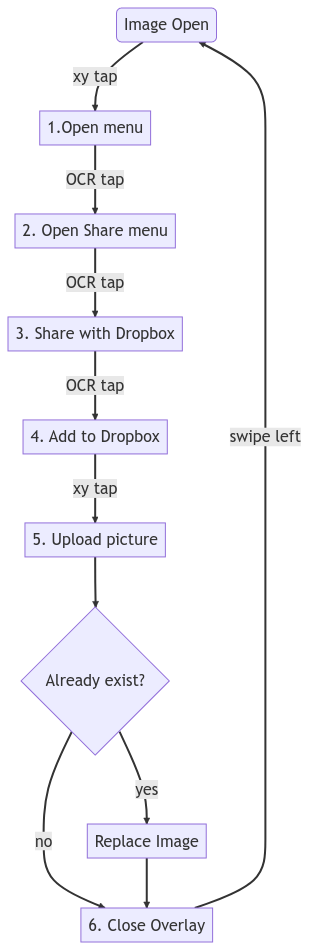
The process that was followed can be seen in Appendix I
Approach
Below I will outline some of the more interesting aspects of this problem/ code, though the full script (in all of its horror) can be found on GitHub here OllieF/whatsapp-android-image-scraper.
Device Input
To interact with the Android device, the adb input command was used to send the positional coordinates for each tap or swipe. For example, to select the WhatsApp menu button, the following python command was used:
device.shell("input tap 1000 150")
This works well when the position of the element will never change, though if the device changes (coordinates are the pixels, which will differ between phones) or the element may be in different locations. To deal with this, OCR was used, which would in-point the location of text on the screen.
Optical Character Recognition
For dynamic text location and validate of steps (i.e., had an action been completed successfully), a screenshot of the current screen was taken and tesseract used to identify all text on the screen. Tesseract was then able to return the text, and it's confidence, along with the x and y, and height and width values. From there, the mid-point of the text can then be identified (x + (0.5 * w), y + (0.5 * h)) and used through the tap input.
Example of text extraction:
import pytesseract
data = pytesseract.image_to_data("screen.png", config="--oem 3 --psm 4", lang="eng")
for i, line in enumerate(data.splitlines()):
if i == 0:
# ignore header line
continue
el = line.split()
if len(el) > 11:
# If there is text that has been identified
text = el[11]
print(
f"x={int(el[6])}",
f"y={int(el[7])}",
f"w={int(el[8])}",
f"h={int(el[9])}",
f"confidence={float(el[10])}",
f"text={el[11]}",
sep="\\t"
)
This would produce output similar to:
plain text
x=57 y=34 w=93 h=29 confidence=96.618729 text=13:17
x=927 y=34 w=99 h=31 confidence=32.933006 text=70%
x=205 y=113 w=177 h=48 confidence=96.494835 text=First
x=398 y=113 w=96 h=38 confidence=96.352654 text=Name
x=205 y=167 w=200 h=47 confidence=96.755676 text=16/09/2022,
x=420 y=177 w=87 h=28 confidence=96.616661 text=19:48
x=738 y=132 w=51 h=48 confidence=81.023743 text=w
x=1012 y=170 w=12 h=12 confidence=88.878616 text=°
To-dos
The code currently works, but barely. I have not seriously taken into account things like lags, failed steps, and reusability (as this is only a personal project). However, here are some things I want still need to change:
Refactor - Add a concept of steps in which the following takes place: - Action - an input gets made - Collection - screenshot gets taken and data collected - Validation - a step is checked for completeness This should then allow for a single place to manage things like retry loops, error handling, logging, etc. Current thinking is either doing this via pipes (as in pandas df pipes), using decorators around functions, or introducing proper OOP.
Robustness - Take into account failed steps, pop-ups, slow uploads, end-conditions, etc
Extensible - Make it more generally usable as currently a lot of assumptions are made around my phone/ model/ requirement (if interest - let me know)
Appendix I
The following process is taken: